
دستور cut لینوکس به شما امکان می دهد بخش هایی از متن را از فایل ها یا جریان های داده استخراج کنید.
این دستور برای کار با داده های محدود شده مانند فایل های CSV مفید می باشد و در این آموزش روش استفاده از دستور cut در خط فرمان لینوکس را توضیح خواهیم داد.
دستور cut یکی از قدیمی ترین کارها در دنیای یونیکس می باشد و اولین کار را به عنوان بخشی از AT&T System III UNIX انجام داد.
شما همچنین می توانید با دستور زیر بررسی نمایید که کدام نسخه دستور cut بر روی کامپیوتر شما نصب شده است.
cut --version
اگر در خروجی GNU coreutils را مشاهده کردید دارای نسخه ایی هستید که ما در این مقاله به توضیح آن خواهیم پرداخت.
همه نسخه های cut دارای برخی از این قابلیت ها هستند، اما نسخه لینوکس دارای پیشرفت هایی است که به آن اضافه شده است.
دستوراتی که استفاده می کنیم یکسان هستند و هر کاری که می توانید برای یک جریان ورودی با cut انجام دهید می تواند بر روی یک خط متن از یک فایل انجام شود.
به طور کلی می توان گفت که دستور cut با بایتها، کاراکترها یا فیلدهای محدود کار میکند.
برای انتخاب یک بایت از گزینه -b (بایت) استفاده می نماییم که کدام بایت یا بایت ها را می خواهیم.
در این مورد بایت مورد نظر پنج می باشد و ما رشته how-to geek را با یک | از echo به دستور cut ارسال می کنیم.
echo 'how-to geek' | cut -b 5

بایت پنجم در آن رشته t است بنابراین دستور cut با چاپ کلمه t در پنجره ترمینال پاسخ می دهد.
همچنین برای تعیین محدوده از خط فاصله استفاده می کنیم و برای استخراج بایت های 5 و 11 دستور زیر را اجرا می کنیم:
echo 'how-to geek' | cut -b 5-11

شما می توانید با جدا کردن آنها با کاما چندین بایت یا محدوده را ارائه دهید. برای استخراج بایت 5 و بایت 11 می توان از دستور زیر استفاده نمود:
echo 'how-to geek' | cut -b 5,11

برای دریافت حرف اول هر کلمه می توانیم از این دستور استفاده کنیم:
echo 'how-to geek' | cut -b 1,5,8

اگر از خط فاصله بدون شماره اول استفاده نمایید دستور cut همه چیز را از موقعیت 1 تا عدد برمی گرداند.
اگر از خط فاصله بدون عدد دوم استفاده نمایید دستور cut همه چیز را از شماره اول تا انتهای جریان یا خط برمی گرداند.
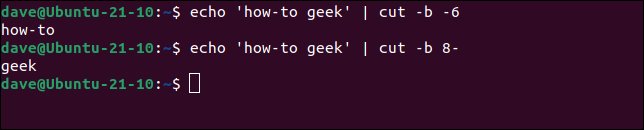
echo 'how-to geek' | cut -b -6
echo 'how-to geek' | cut -b 8-
استفاده از دستور cut در کاراکتر Characters
استفاده از دستور cut با کاراکترها تقریباً مشابه استفاده از آن با بایت ها می باشد.
در هر دو مورد باید مراقب شخصیت های پیچیده بود و با استفاده از گزینه -c (کاراکتر) دستور cut از نظر کاراکتر کار می کند.
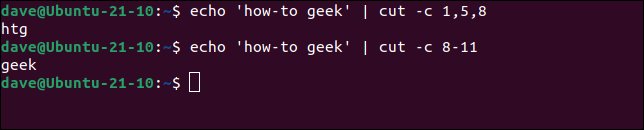
echo 'how-to geek' | cut -c 1,5,8
echo 'how-to geek' | cut -c 8-11
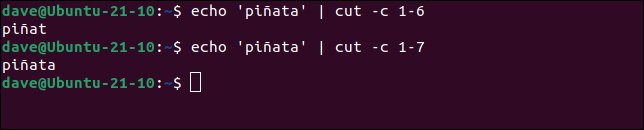
این یک کلمه شش حرفی است بنابراین درخواست cut برای برگرداندن کاراکترها از یک به شش باید کل کلمه را برگرداند.
اما اینطور نیست و یک کاراکتر کوتاه است برای دیدن کل کلمه باید شخصیت های یک تا هفت را بخواهیم.
echo 'piñata' | cut -c 1-6
echo 'piñata' | cut -c 1-7
مسئله این است که کاراکتر ñ در واقع از دو بایت تشکیل شده است و ما می توانیم این را به راحتی ببینیم.
ما یک فایل متنی کوتاه داریم که حاوی این خط متن است:
cat unicode.txt

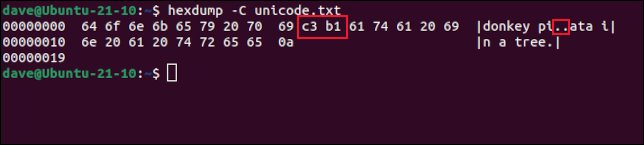
ما آن فایل را با ابزار hexdump بررسی می کنیم. با استفاده از گزینه -C جدولی از ارقام هگزا دسیمال با معادل ASCII در سمت راست به ما نمایش می دهد.
در جدول ASCII کلمه ñ نشان داده نشده است ولی در عوض نقطه هایی وجود دارد که نشان دهنده دو کاراکتر غیر قابل چاپ هستند.
اینها بایت هایی هستند که در جدول هگزادسیمال مشخص شده اند.
hexdump -C unicode.txt
این دو بایت توسط برنامه نمایشگر در این مورد، پوسته Bash برای شناسایی “ñ” استفاده می شود.
بسیاری از کاراکترهای یونیکد از سه یا چند بایت برای نمایش یک کاراکتر استفاده می کنند.
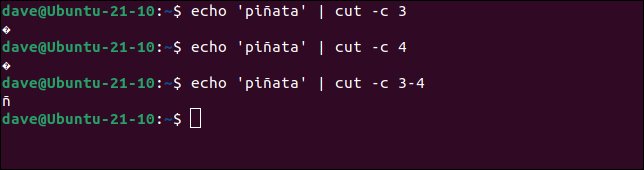
اگر کاراکتر 3 یا 4 را بخواهیم آیکن یک کاراکتر غیرچاپی نشان داده میشود و اگر بایت های 3 و 4 را بخواهیم، پوسته آنها را به عنوان ñ تفسیر می کند.
echo 'piñata' | cut -c 3
echo 'piñata' | cut -c 4
echo 'piñata' | cut -c 3-4



 در ویندوز 10")

















